GPT(ChatGPT)に代表される大規模言語モデル(Large Language Model)の開発と発表が次々とされています。
大規模言語モデルを用いたアプリケーションを開発したいと思う方々もいるかと思いますが、どんなモデルがあるのか探すだけでも大変と感じている方もいるのではないかと思います。
このページでは大規模言語モデルを使ったアプリケーション開発者向けに、
商用利用可能なオープンソースの大規模言語モデルの情報を紹介します。
【注意事項】
- 既にサービス化されているもの(OpenAI、Azure)などは対象外とします。
- ソースに基づいて記載し、誤りがないよう注意していますが、誤りがない可能性もゼロではありませんので、最終的な確認・判断は各自お願いできればと思います。
- このページでは大規模言語モデルのリリースを見つけ次第情報を更新していく予定です。
なお各モデルのパフォーマンスはこちらがわかりやすいです。
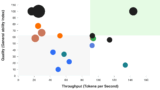
Comparison of AI Models across Intelligence, Performance, and Price
Comparison and analysis of AI models across key performance metrics including quality, price, output speed, latency, context window & others.
商用利用可能な大規模言語モデル一覧
Hermes 4
開発主体:Nous Research
発表日:August 5, 2025
Llama3.1をNous Reseachにより追加学習。RefusalBenchでSOTAを達成。
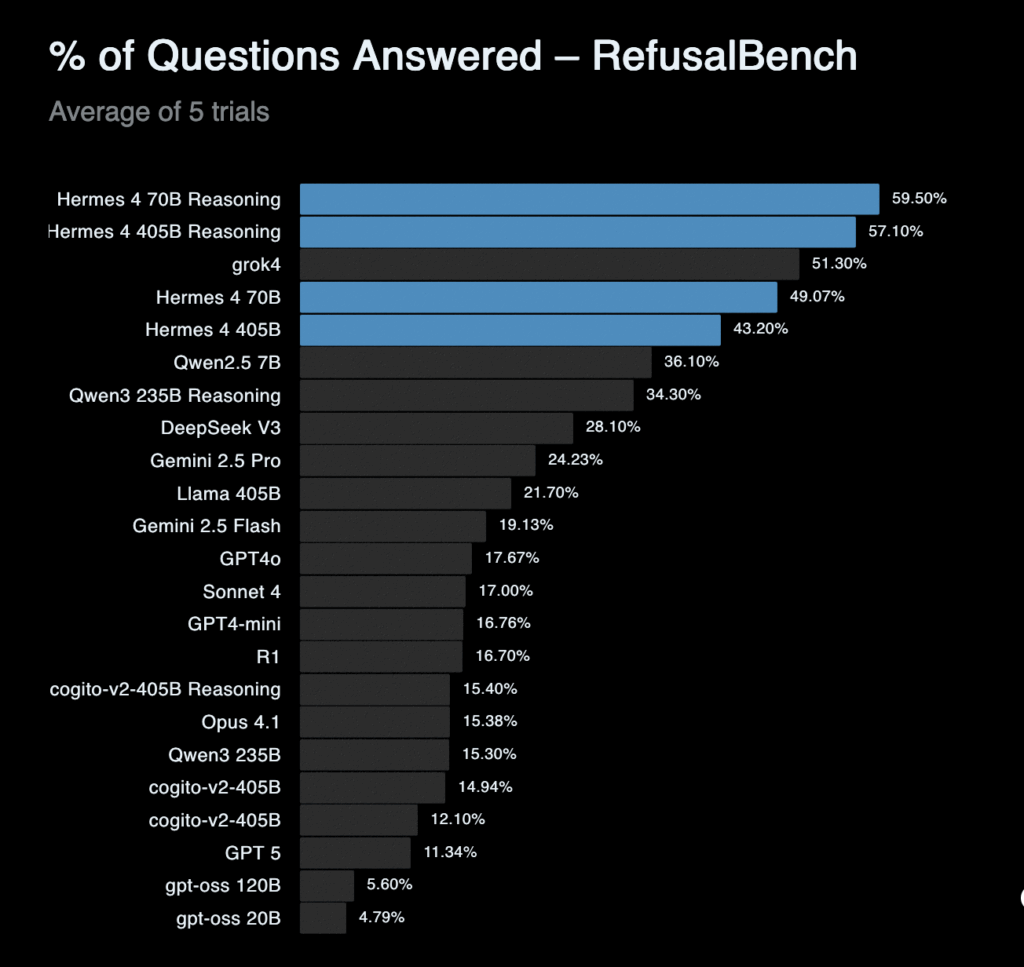 Hermes 4ホームページより抜粋
Hermes 4ホームページより抜粋

Hermes 4 - Nous Research
Experience the next generation of Nous Chat, featuring Hermes 4 - revamped

NousResearch/Hermes-4-70B · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
gpt-oss
開発主体:Open AI
発表日:August 5, 2025
Open AIより公開モデルとして、gpt-ossが発表。o3に匹敵するベンチマーク精度。
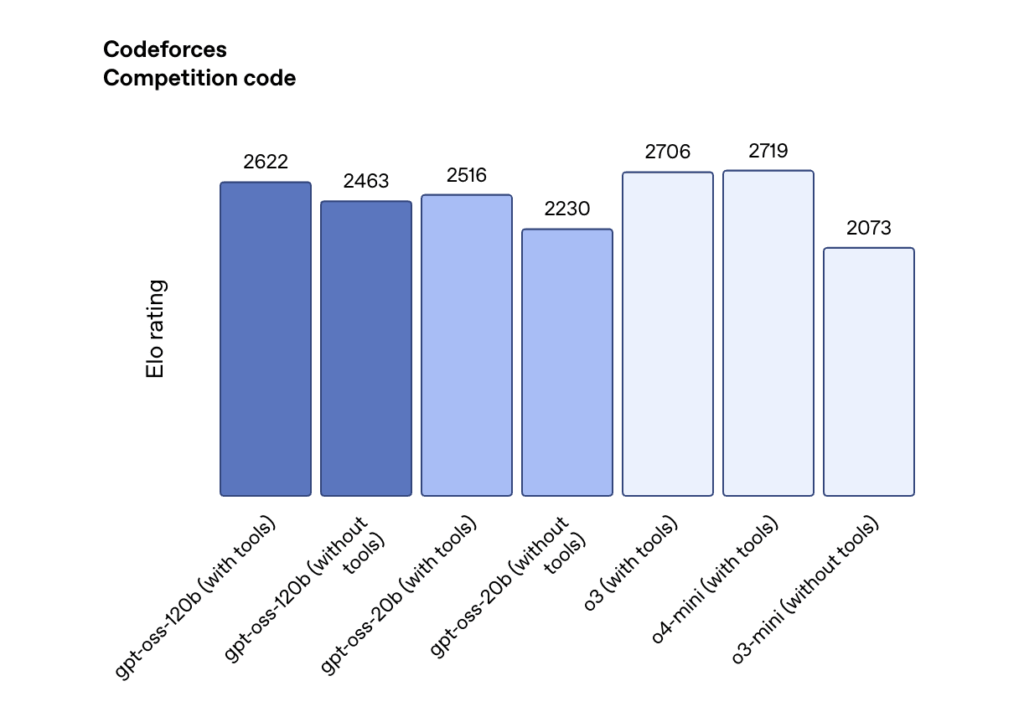 サイトより抜粋
サイトより抜粋

openai/gpt-oss-120b · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
Qwen3
開発主体:アリババ
発表日:April 29, 2025
驚異のDeepseek超え。o4レベルでこれでもう十分じゃないかという声がちらほら。

GitHub - QwenLM/Qwen3: Qwen3 is the large language model series developed by Qwen team, Alibaba Cloud.
Qwen3 is the large language model series developed by Qwen team, Alibaba Cloud. - QwenLM/Qwen3

Qwen3: Think Deeper, Act Faster
QWEN CHAT GitHub Hugging Face ModelScope Kaggle DEMO DISCORDIntroduction Today, we are excited to announce the release of Qwen3, the latest addition to the Qwen...
Deepseek-R1
開発主体:Deepseek
発表日: January 15, 2025
ご存知の方も多いと思いますが、Deepseek-R2は中国発ベンチャーであるDeepseekよりリリースされたLLMでその性能はOpen AIのo1に匹敵するとされています。
Nvidiaの株価暴落を引き起こし、社会的にも話題になっているOSS LLMの大本命です。
またサイバーエージェントから日本語でファインチューニングされたモデルがリリースされています。
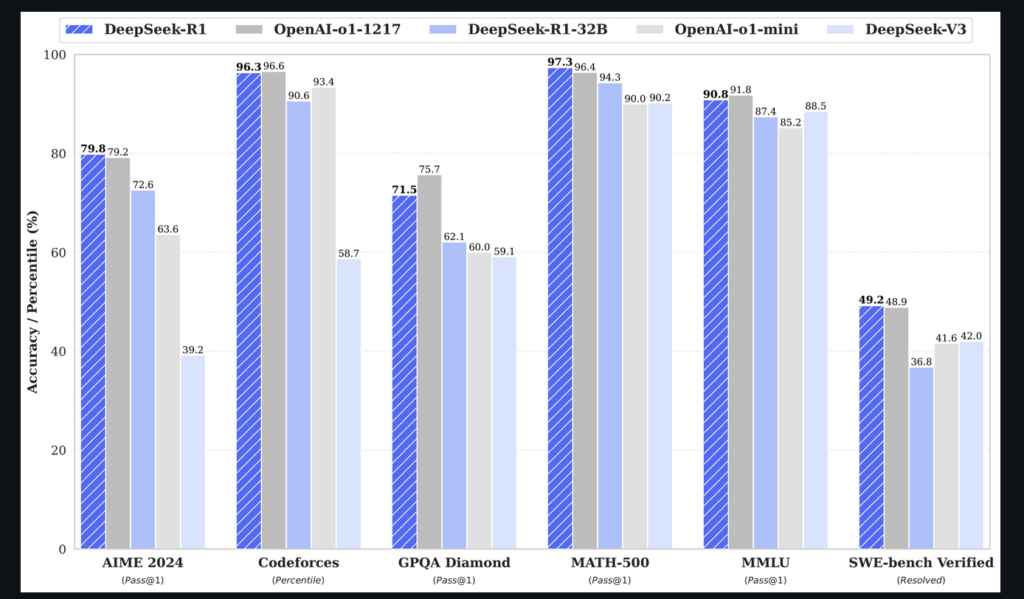

GitHub - deepseek-ai/DeepSeek-R1
Contribute to deepseek-ai/DeepSeek-R1 development by creating an account on GitHub.

cyberagent/DeepSeek-R1-Distill-Qwen-32B-Japanese · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
Sarashina
開発主体:SB Institution
発表日:Nov 8, 2024
ソフトバンクの子会社であるSB Institutionが開発した日本語特化のモデル。
その後小型モデル(Sarashina2.2)も発表

SB Intuitions、日本語に特化した4,000億クラスのパラメータを持つモデルを公開 アカデミアや産業界の研究開発に資するために、4,000億クラスのパラメータを持つ日本語LLMを公開 | プレスリリース | SB Intuitions株式会社
SB Intuitions、日本語に特化した4,000億クラスのパラメータを持つモデルを公開 アカデミアや産業界の研究開発に資するために、4,000億クラスのパラメータを持つ日本語LLMを公開

sbintuitions/sarashina2-8x70b · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
Qwen2
開発主体:アリババ
発表日:June 7, 2024
アリババの開発したLLMで最大のモデルがQwen-72B。Llama3より精度は上とのこと。
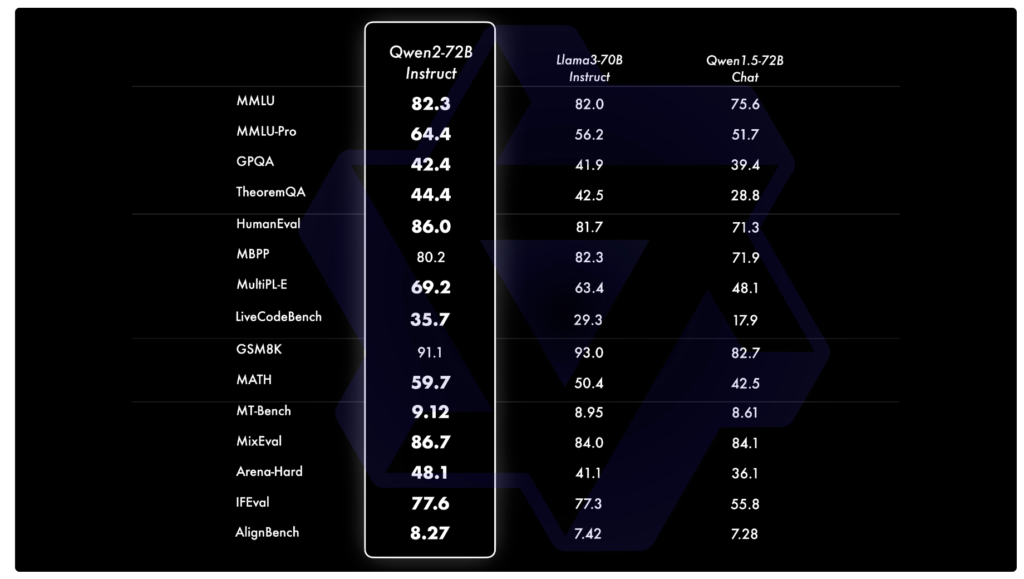 ブログより抜粋
ブログより抜粋
Hello Qwen2
GITHUB HUGGING FACE MODELSCOPE DEMO DISCORDIntroduction After months of efforts, we are pleased to announce the evolution from Qwen1.5 to Qwen2. This time, we b...

Qwen
Alibaba Cloud's general-purpose AI models. Qwen has 33 repositories available. Follow their code on GitHub.
Gemma 2 Baku 2B
開発主体: rinna
発表日:Oct. 3, 2024
License: Gemma Terms of Use
rinna社よりGemma 2の日本語継続事前学習モデルが公開されました。いくらなんでも早すぎじゃない??!

Gemma 2の日本語継続事前学習モデル「Gemma 2 Baku 2B」シリーズを公開|rinna株式会社
Gemma 2 2Bのテキスト生成能力やコストパフォーマンスを活かしつつ日本語能...
日本語版 Gemma 2 2B
開発主体: Google
発表日:Oct. 3, 2024
License: Gemma Terms of Use
Google社より日本語対応したGemma2 が公開されました。

google/gemma-2-2b-jpn-it · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.

日本語版 Gemma 2 2B を公開
Google は、AI をあらゆる人にとって役立つものにすることを目指し、開発者コミュニティが独自の言語や文化に合わせて AI を活用し実装できることを目指しています。その一環として、今年の I/O では、インドの開発者が Gemma をファイン チューニングして、12 のインド言語でテキストを理解し生成することに成功...
GRIN MoE
開発主体: Microsoft
発表日:Jun. 26, 2024
License: MIT
わずか6.6Bのアクティブパラメータを持つGRIN MoEは、特にコーディングと数学のタスクにおいて、優れたパフォーマンスを達成したとのこと。
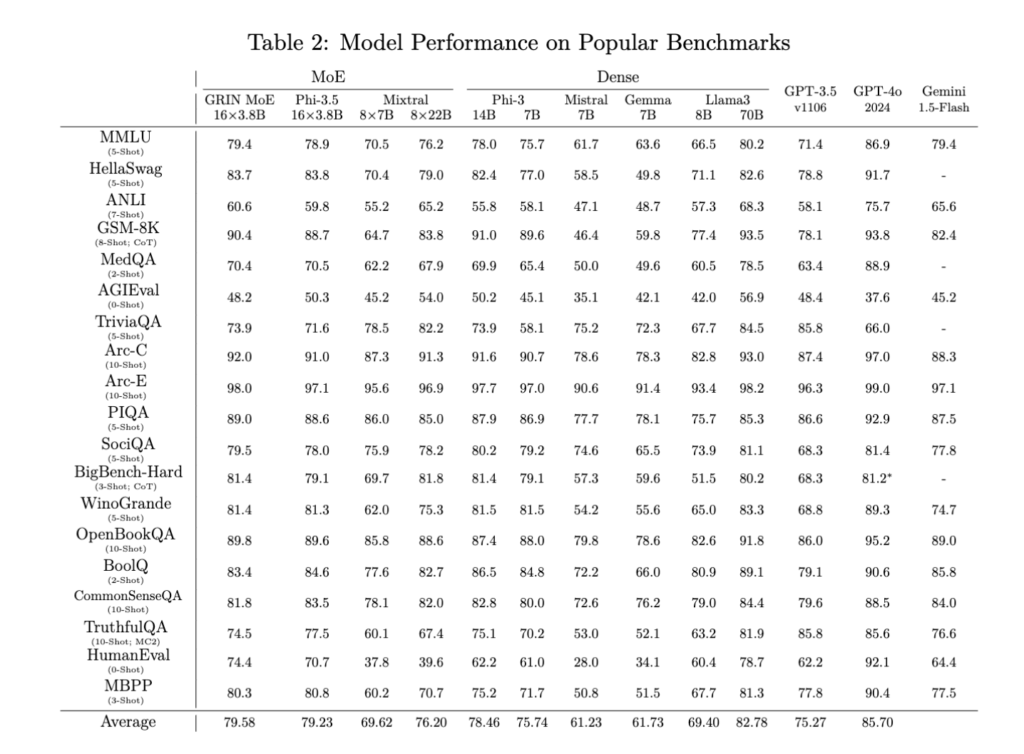 https://github.com/microsoft/GRIN-MoE/blob/main/GRIN_MoE.pdfより抜粋
https://github.com/microsoft/GRIN-MoE/blob/main/GRIN_MoE.pdfより抜粋

GitHub - microsoft/GRIN-MoE: GRadient-INformed MoE
GRadient-INformed MoE. Contribute to microsoft/GRIN-MoE development by creating an account on GitHub.
Llama-3-ELYZA-JP
開発主体: ELYZA
発表日:Jun. 26, 2024
ELYZAよりLlama3ベースで構築した日本語対応モデルがリリース。日本語に関してはGPT-4を上回るとのこと。
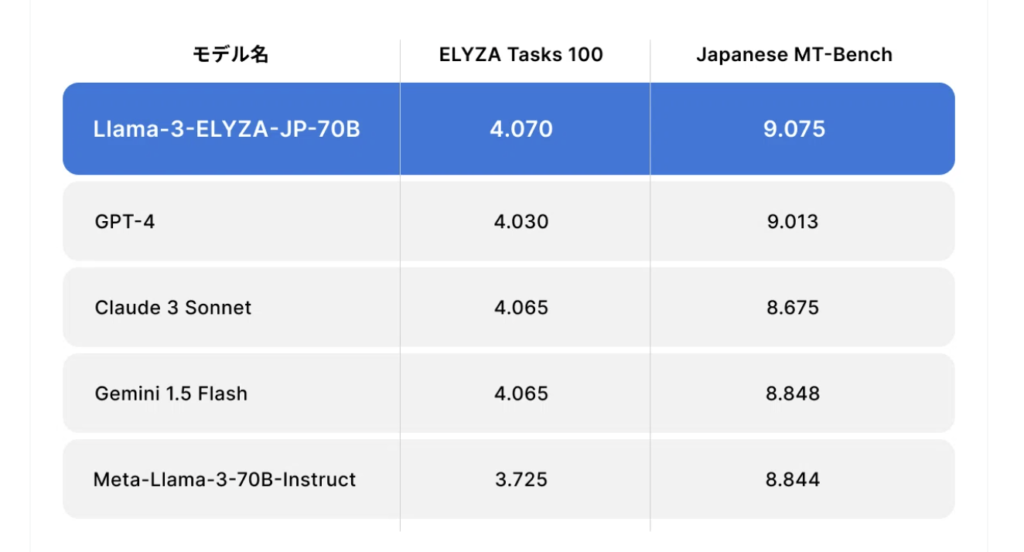 ホームページより抜粋
ホームページより抜粋

「GPT-4」を上回る日本語性能のLLM「Llama-3-ELYZA-JP」を開発しました|ELYZA, Inc.
本記事のサマリー ELYZA は、「Llama-3-ELYZA-JP」シリーズの研究開発成果を公開しました。700億パラメータのモデルは、日本語の生成能力に関するベンチマーク評価 (ELYZA Tasks 100、Japanese MT-Bench) で「GPT-4」を上回る性能を達成しました。各モデルは Meta ...
Phi-3
開発主体: Microsoft
発表日:Apr. 23, 2024
Microsoftからでたオープンソースのモデル。モデルのサイズが小さいにもかかわらず、chatGPT-3.5に匹敵する精度が出ていることが特徴。もはやLLM(Large Language Model)ではなく、SLM(Small Language Model)と呼ばれる。
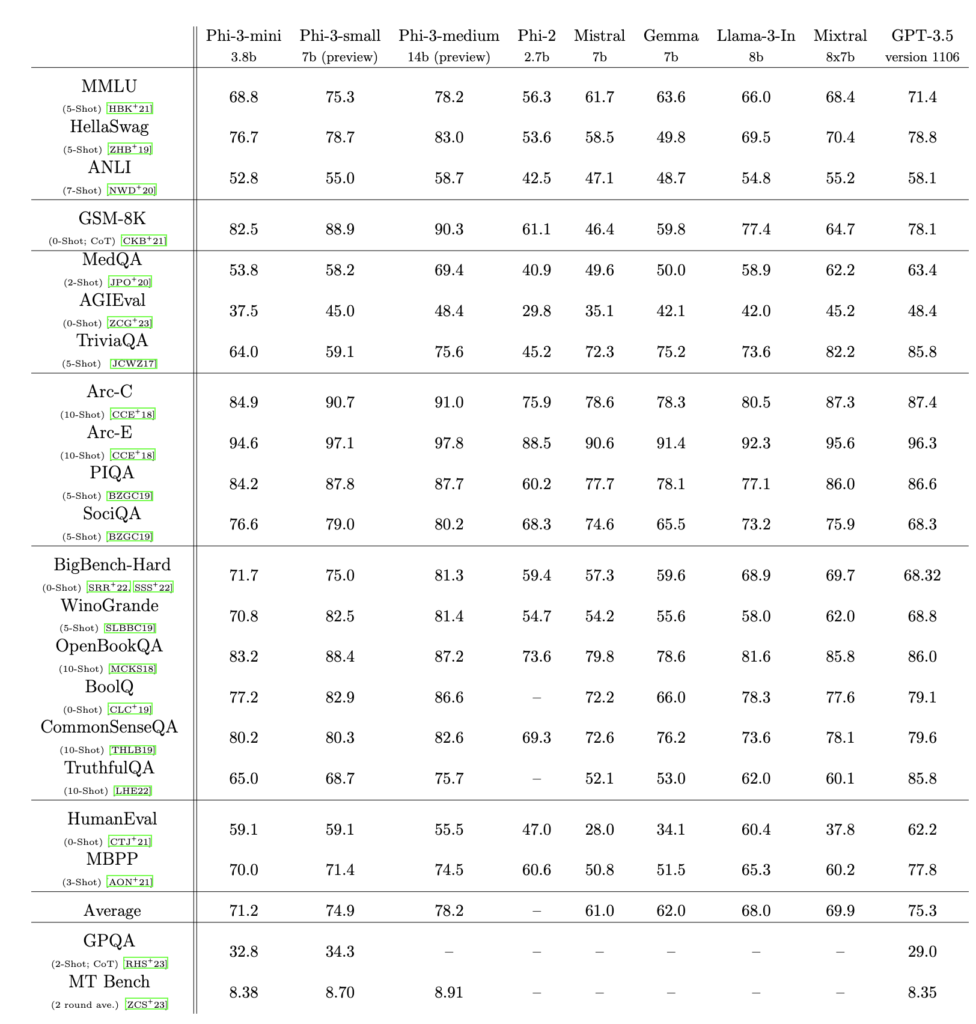 精度比較結果。Phi-3 Technical Report:A Highly Capable Language Model Locally on Your Phoneより抜粋。
精度比較結果。Phi-3 Technical Report:A Highly Capable Language Model Locally on Your Phoneより抜粋。

Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmar...

Introducing Phi-3: Redefining what's possible with SLMs | Microsoft Azure Blog
We are excited to introduce Phi-3, a family of small open models offering groundbreaking performance, developed by Microsoft. Learn more.
Llama3シリーズ
開発主体: meta
発表日:Apr. 18, 2024 -> Sep. 25. 2024
Llama2の後継。大本命となりそう。
2024年9月25日にLlama3.2がでてきました。ただしLlama3.1から言語モデルの精度はかわってなさそうです。

Llama can now see and run on your device - welcome Llama 3.2
We’re on a journey to advance and democratize artificial intelligence through open source and open science.

Llama 3.2: Revolutionizing edge AI and vision with open, customizable models
Today, we’re releasing Llama 3.2, which includes small and medium-sized vision LLMs, and lightweight, text-only models that fit onto edge and mobile devices.

Introducing Meta Llama 3: The most capable openly available LLM to date
Today, we’re introducing Meta Llama 3, the next generation of our state-of-the-art open source large language model. In the coming months, we expect to share ne...
Meta、無料で商用可の新LLM「Llama 3」、ほぼすべてのクラウドでアクセス可能に
Metaは、オープンソースのLLM最新版「Llama 3」をパラメータ80億と700億の2モデルで公開した。AWSやAzure、Google Coudなどで利用可能になる。誤った拒否率が大幅に減少したとしている。
DBRX
開発主体:Databricks
発表日:Mar. 27, 2024
サイズは1320億パラメータ。

Introducing DBRX: A New State-of-the-Art Open LLM
Explore DBRX, the advanced open-source LLM from Databricks redefining model efficiency and quality, leading in AI benchmarks.
Karasu / Qarasu
開発主体:Lightblue
発表日:Dec. 29 2023
Lightblue社より日本語LLMとして、KarasuシリーズとQarasuシリーズがリリースされました。
Karasuシリーズは70億パラメータのモデル、Qarasuシリーズは140億パラメータのモデルであり、既存の日本語公開モデルの中で最高性能とのこと。
https://huggingface.co/collections/lightblue/karasu-658e78e9188f3934c6fb701e
https://prtimes.jp/main/html/rd/p/000000053.000038247.html
Swallow
開発主体:東京工業大学
Lama2 を日本語で継続学習を実施。
Meditron (医療系)
開発主体:EPFL
発表日:Nov 27. 2023
ライセンス:
(Model) LLAMA 2 COMMUNITY LICENSE AGREEMENT
(Code) APACHE 2.0 LICENSE
初の医療特化型の商用利用可能なオープンソースLLM。ドメイン特化型の存在意義についていろいろ議論が出ていますが、これについてはGPT3.5に匹敵とのこと。
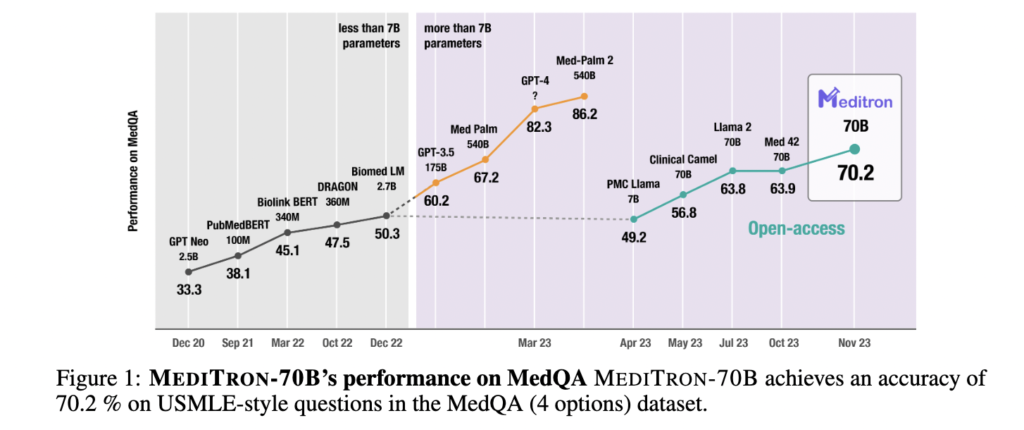 論文より抜粋。
論文より抜粋。

MEDITRON-70B: Scaling Medical Pretraining for Large Language Models
Large language models (LLMs) can potentially democratize access to medical knowledge. While many efforts have been made to harness and improve LLMs' medical kno...

Paper page - MEDITRON-70B: Scaling Medical Pretraining for Large Language Models
Join the discussion on this paper page
Stockmark-13b (ビジネス)
開発主体:ストックマーク
発表日:Oct 10. 2023
ストックマーク社が開発したビジネス領域に特化したLLM。ビジネス領域に関する質問応答に高精度達成。

ストックマーク、ビジネスでも信頼できる130億パラメータLLMをオープンソースで公開 | ストックマーク株式会社
ストックマーク株式会社は、AWSジャパンの「AWS LLM 開発支援プログラム」を活用し、日本語単独としては最大規模になる130億パラメータのLLMを公開致しました。

stockmark/stockmark-13b · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
LLM-jp-13B/LLM-jp-172B
開発主体:NII(LLM.jp)
発表日: Oct 20. 2023 -> 2024.09.25
130億の大規模言語モデル(LLM)の構築。2024年9月に更新版がでてきました。
(追記: 172Bも出ておりました)

LLM-jp-3 172B: オープンかつ日本語に強いGPT-3級大規模言語モデル | 国立情報学研究所 大規模言語モデル研究開発センター
国立情報学研究所 大規模言語モデル研究開発センターのWebサイトです。

LLM-jp-3 1.8B・3.7B・13B の公開 | 国立情報学研究所 大規模言語モデル研究開発センター
国立情報学研究所 大規模言語モデル研究開発センターのWebサイトです。

130億パラメータの大規模言語モデル「LLM-jp-13B」を構築~NII主宰LLM勉強会(LLM-jp)の初期の成果をアカデミアや産業界の研究開発に資するために公開~ - 国立情報学研究所 / National Institute of Informatics
国立情報学研究所は、情報学という新しい研究分野での「未来価値創成」を目指すわが国唯一の学術総合研究所として、ネットワーク、ソフトウェア、コンテンツなどの情報関連分野の新しい理論・方法論から応用展開までの研究開発を総合的に推進しています。
PLaMo – Preferred Language Model
開発主体:Preferred Networks
発表日:Sep 28. 2023
130億のパラメータで、日英2言語をあわせた能力で世界トップレベルの性能を達成
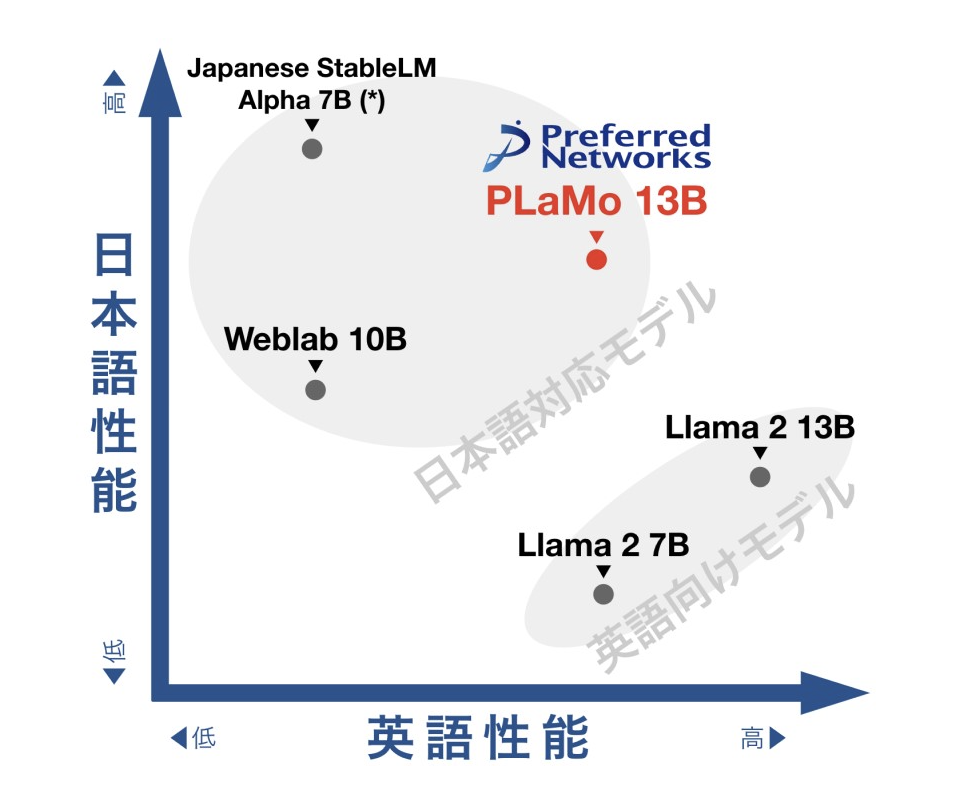 大規模言語モデルの性能比較 Preferred Networksのホームページより抜粋
大規模言語モデルの性能比較 Preferred Networksのホームページより抜粋

日英2言語対応の大規模言語モデルPLaMo-13Bを研究・商用利用可能なオープンソースソフトウェアライセンスで公開 - 株式会社Preferred Networks
株式会社Preferred Networks(本社:東京都千代田区、代表取締役 最高経営責任者:西川徹、以下、PFN)は、開発した130億パラメータの事前学習済み大規模言語モデル PLaMo™-13B(Preferred Language Model、プラモ)を、研究・商用で利用可能なオープンソースソフトウェア(OSS
ELYZA-japanese-Llama-2-7b/13b
開発主体: ELYZA
発表日:Aug 28. 2023 -> Dec 12. 2023
ELYZAよりLlama2(70億パラメータ)ベースの日本語LLMが公開されました。
日本語LLMとしては最高精度であると発表されています。
(追記 Dec 12. 2023)
「Llama 2 13B」をベースとした商用利用可能な日本語LLM、「ELYZA-japanese-Llama-2-13b」が開発されました。GPT-3.5を超え、現時点日本語LLMで最高性能となっています。
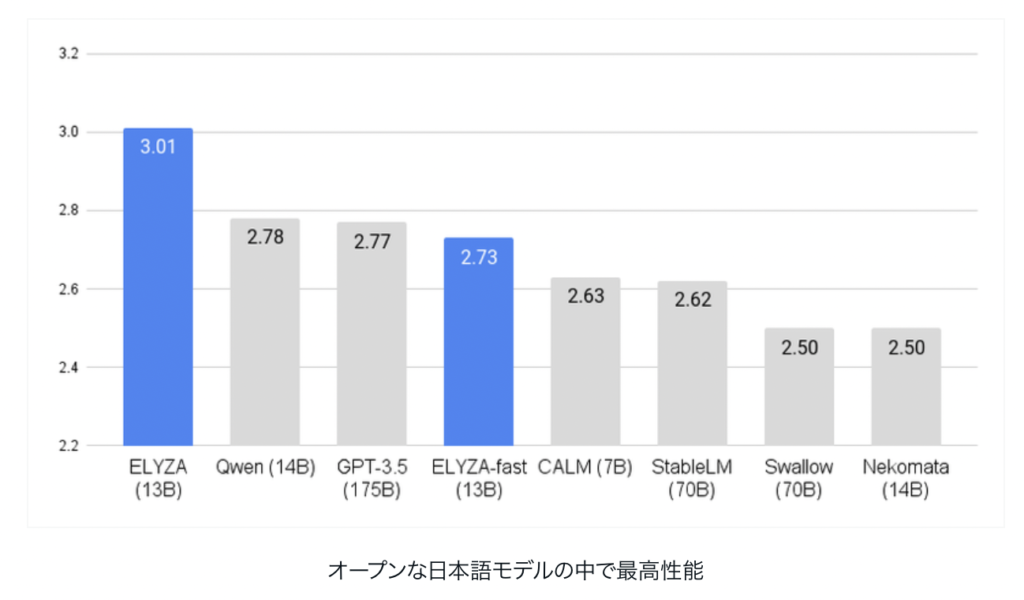 下記リリースノートより抜粋
下記リリースノートより抜粋

130億パラメータの「Llama 2」をベースとした日本語LLM「ELYZA-japanese-Llama-2-13b」を公開しました(商用利用可)|株式会社ELYZA 公式ブログ
本記事のサマリー ELYZA は「Llama 2 13B」をベースとした商用利用可能な日本語LLMである「ELYZA-japanese-Llama-2-13b」シリーズを一般公開しました。前回公開の 7B シリーズからベースモデルおよび学習データの大規模化を図ることで、既存のオープンな日本語LLMの中で最高性能、GP...

Metaの「Llama 2」をベースとした商用利用可能な日本語LLM「ELYZA-japanese-Llama-2-7b」を公開しました|ELYZA, Inc.
本記事のサマリー ELYZAが「Llama 2」ベースの商用利用可能な日本語LLM「ELYZA-japanese-Llama-2-7b」を一般公開 性能は「GPT-3.5 (text-davinci-003)」に匹敵、日本語の公開モデルのなかでは最高水準 Chat形式のデモや評価用データセットも合わせ...
japanese-large-lm
開発主体: LINE
発表日:Aug 14. 2023
LINEより日本語の大規模言語モデルがリリースされました。LINE独自でコーパスでトレーニングしたとのこと。36億パラメータと比較的小さいので動かしやすいかも。
Instruction tuningしたモデルを近日中に公開するとのこと。ありがたいです。
36億パラメータの日本語言語モデルを公開しました
こんにちは。LINEのNLP Foundation Devチームの清野舜と高瀬翔とoverlastです。LINEでは2020年11月から日本語に特化した大規模言語モデル「HyperCLOVA」の構築と応用に関わる研究開発に取り組んできましたが、この「HyperCLOVA」と並行するかたちで複数の...
Instruction tuningされたバージョンが商用利用可能なライセンスでリリースされました!!
発表日:Aug 18. 2023

Instruction Tuningにより対話性能を向上させた3.6B日本語言語モデルを公開します
こんにちは。NLP Foundation Devチームの小林滉河(@kajyuuen)と水本智也(@tomo_wb)です。NLP Foundation Devチームでは言語モデルの構築やモデルの応用・評価について取り組んでいます。今回はその取り組みの一つである「japanese-large-lm-...
Japanese StableLM Alpha
開発主体: Stability AI Japan
発表日:Aug 10. 2023 -> Oct 10. 2023 -> Oct 25. 2023
Stability AI Japanより日本語大規模言語モデルがリリース。日本語の精度では圧倒的なようです。

ホームページより抜粋
インストラクションモデルも商用利用可能となりました(2023/10/11 -> 2023/10/25)

Stability AI
Multimodal media generation and editing tools designed for the best in the business. No creative challenge too big, no timeline too tight. Get to production wit...
Llama 2
開発主体:Meta
発表日:July 18. 2023
Metaより、700億パラメータのモデルがリリースされました。

Meta and Microsoft Introduce the Next Generation of Llama
Today, we’re introducing the availability of Llama 2, the next generation of our open source large language model.

Industry Leading, Open-Source AI | Llama
Discover Llama 4's class-leading AI models, Scout and Maverick. Experience top performance, multimodality, low costs, and unparalleled efficiency.

Llama 2: Open Foundation and Fine-Tuned Chat Models | Research - AI at Meta
In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to...
XGen
開発主体:Salesforce
発表日:Jun 28. 2023
XGen-7B-4K-baseとXGen-7B-8K-baseはapach2.0だが、XGen-7B-{4K,8K}-instは研究目的のみ。
Falcon
開発主体:Technology Innovation Institute
発表日:Jun 5. 2023
ライセンス:Apache 2.0
Falconはアラブ首長国連邦にある研究機関Technology Innovation Instituteにより開発されました。ウェブ上から集めた大規模なデータセットであるRefinedWebをベースにFalconは訓練されています。
400億個のパラメーターをもつ「Falcon-40B」モデルは、90GBのGPU Memoryが必要とのことで動かすのが結構大変かもしれません。。

The Falcon has landed in the Hugging Face ecosystem
We’re on a journey to advance and democratize artificial intelligence through open source and open science.

Introducing the Technology Innovation Institute’s Falcon Perception Making Advanced AI accessible and Available to Everyone, Everywhere
Falcon LLM is a generative large language model (LLM) that helps advance applications and use cases to future-proof our world.

tiiuae/falcon-40b · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
open-calm
開発主体:サイバーエージェント
発表日:May 27. 2023 -> Nov 2 2023
ライセンス:CC BY-SA 4.0
対応言語:日本語
サイバーエージェントが最大68億パラメータの日本語LLM(大規模言語モデル)を開発
バージョン2がリリースされました(Nov 2 2023)

サイバーエージェント、最大68億パラメータの日本語LLM(大規模言語モデル)を一般公開 ―オープンなデータで学習した商用利用可能なモデルを提供―
サイバーエージェントの新たな取り組みやサービス情報など、当社のニュースリリースを掲載しています。

独自の日本語LLM(大規模言語モデル)のバージョン2を一般公開 ―32,000トークン対応の商用利用可能なチャットモデルを提供―
サイバーエージェントの新たな取り組みやサービス情報など、当社のニュースリリースを掲載しています。
rinna 日本語LLM
開発主体:rinna
発表日:May 17. 2023
ライセンス:MIT License

プレスリリース・ニュースリリース配信シェアNo.1|PR TIMES
OpenLLaMA
開発主体:Berkeley AI Research
発表日: May 4. 2023

OpenLM Research
Open source large language model research. OpenLM Research has 2 repositories available. Follow their code on GitHub.

openlm-research (OpenLM Research)
Open source language model research
MPT
開発主体:MosaicML
発表日: May 5, 2023 -> Jun 22, 2023
7Bをこえる30Bのモデルが発表されました。

AI Research | Databricks Blog
Read the Databricks AI Research category on the company blog for the latest employee stories and events.

Introducing MPT-7B: A New Standard for Open-Source, Commercially Usable LLMs
Introducing MPT-7B, the first entry in our MosaicML Foundation Series. MPT-7B is a transformer trained from scratch on 1T tokens of text and code. It is open so...
モデルURL(7Bモデル):
(Base model) https://huggingface.co/mosaicml/mpt-7b
(StoryWriter):https://huggingface.co/mosaicml/mpt-7b-storywriter
(Instruction): https://huggingface.co/mosaicml/mpt-7b-instruct
利用手順:

Contact Us - Databricks
Contact us if you have any questions about Databricks products, pricing, training or anything else. Activate your 14-day full trial today!
RedPajama
開発主体:Together
発表日:May 5,2023
独自に用意したRedPajama base datasetで訓練されたモデル。

Releasing 3B and 7B RedPajama-INCITE family of models including base, instruction-tuned & chat models
StableLM
開発主体: Stability.ai
発表日: April 19, 2023

Stability AI Launches the First of its Stable LM Suite of Language Models — Stability AI
Stability AI's open-source Alpha version of StableLM showcases the power of small, efficient models that can generate high-performing text and code locally on p...
Dolly-2.0
開発主体:Databricks
発表日:April 12, 2023

Free Dolly: Introducing the World's First Truly Open Instruction-Tuned LLM
Introducing Dolly, the first open-source, commercially viable instruction-tuned LLM, enabling accessible and cost-effective AI solutions.
訓練済みモデルURL:
https://huggingface.co/datasets/databricks/databricks-dolly-15k/blob/main/databricks-dolly-15k.jsonl
Databricks社が独自の会話データセットを作成し、訓練を行ったモデル。
作成データも自由に利用可能。
RWKV
開発主体: BlinkDL
発表日: April, 2023
RNN(Recurrent Neural Network)ベースで構築された大規模言語モデル。

GitHub - BlinkDL/RWKV-LM: RWKV (pronounced RwaKuv) is an RNN with great LLM performance, which can also be directly trained like a GPT transformer (parallelizable). We are at RWKV-7 "Goose". So it's combining the best of RNN and transformer - great performance, linear time, constant space (no kv-cache), fast training, infinite ctx_len, and free sentence embedding.
RWKV (pronounced RwaKuv) is an RNN with great LLM performance, which can also be directly trained like a GPT transformer (parallelizable). We are at RWKV-7 "Goo...

RWKV: Reinventing RNNs for the Transformer Era
Transformers have revolutionized almost all natural language processing (NLP) tasks but suffer from memory and computational complexity that scales quadraticall...
Cerebras-GPT
開発主体:Cerebras
発表日:March 28, 2023

Cerebras-GPT: A Family of Open, Compute-efficient, Large Language Models - Cerebras
Cerebras open sources seven GPT-3 models from 111 million to 13 billion parameters. Trained using the Chinchilla formula, these models set new benchmarks for ac...
関連情報
Chat language models tracker