
ここでは大規模言語モデル関連の論文で気になったものをまとめます。
GPT-4レベルの質問応答タスク性能をLlama 2で実現
論文タイトル:ChatQA: Building GPT-4 Level Conversational QA Models
発表日:Jan 18. 2024
Llama2ベースで作ったモデルが、いくつかのタスクでChatGPTに匹敵する精度を達成したとのこと。
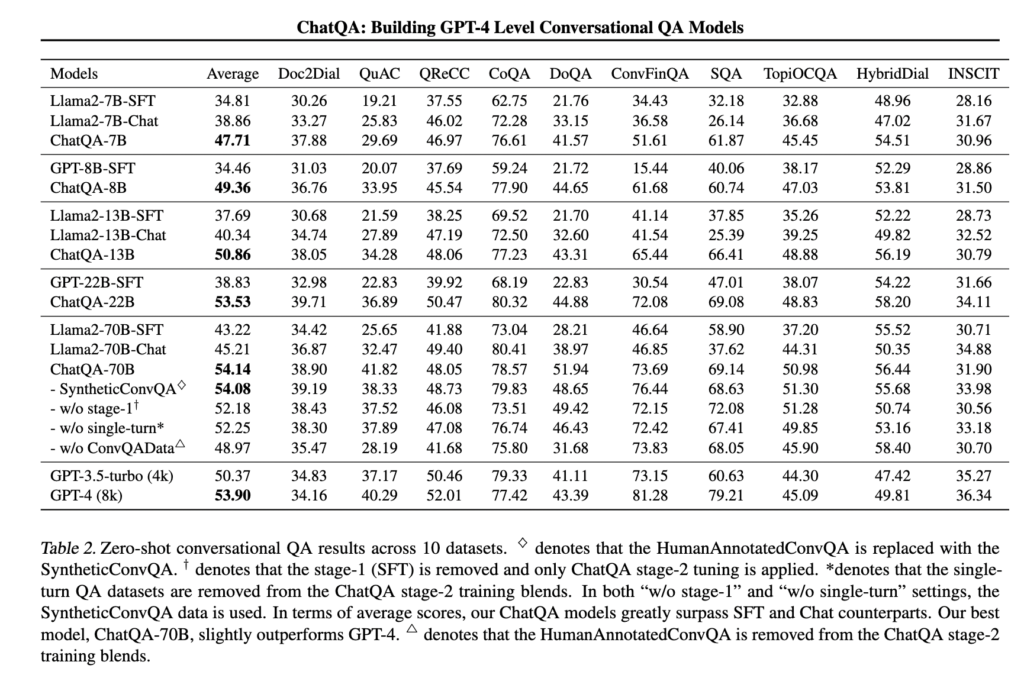

RAGのサーベイ論文
論文タイトル:Retrieval-Augmented Generation for Large Language Models: A Survey
発表日:Dec 18. 2023
RAGのサーベイ論文。研究の変遷やFine-Tuningとの比較について言及しており、参考になります。

ハルシネーションは避けられない
論文タイトル:Calibrated Language Models Must Hallucinate
発表日:Dec 18. 2023
データの品質に関係なく、ハルシネーションは発生するとのこと

最もよく利用さているOSS大規模言語モデル : Llama2
論文タイトル:Llama 2: Open Foundation and Fine-Tuned Chat Models
発表日 July 18. 2023
最もよく利用されているOSSの大規模言語モデルであるLama2の原著論文。

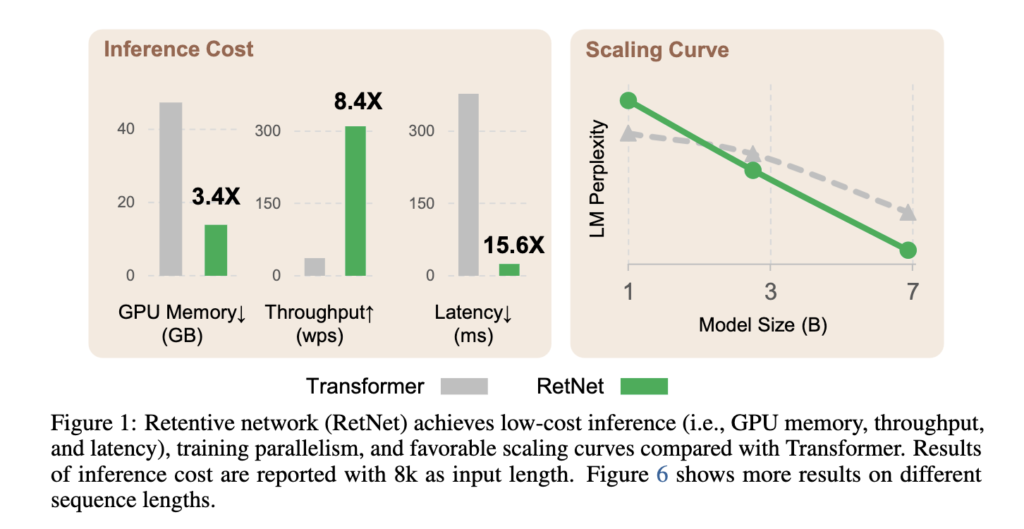
トランスフォーマーを超える効率的なアーキテクチャ:RetNet
論文タイトル:Retentive Network: A Successor to Transformer for Large Language Models
発表日:July 19. 2023
大規模言語モデルの基礎アーキテクチャとして、Retentive Network(RetNet)を提案。トレーニングの並列性、低コストな推論、優れたパフォーマンスを同時に実現します。
Microsoft research

10億トークンに耐えるLLM
論文タイトル:LONGNET: Scaling Transformers to 1,000,000,000 Tokens
発表日:5 July. 2023
Microsoft researchが開発したLONGNETの論文。10億のTokenを処理できるとのこと。
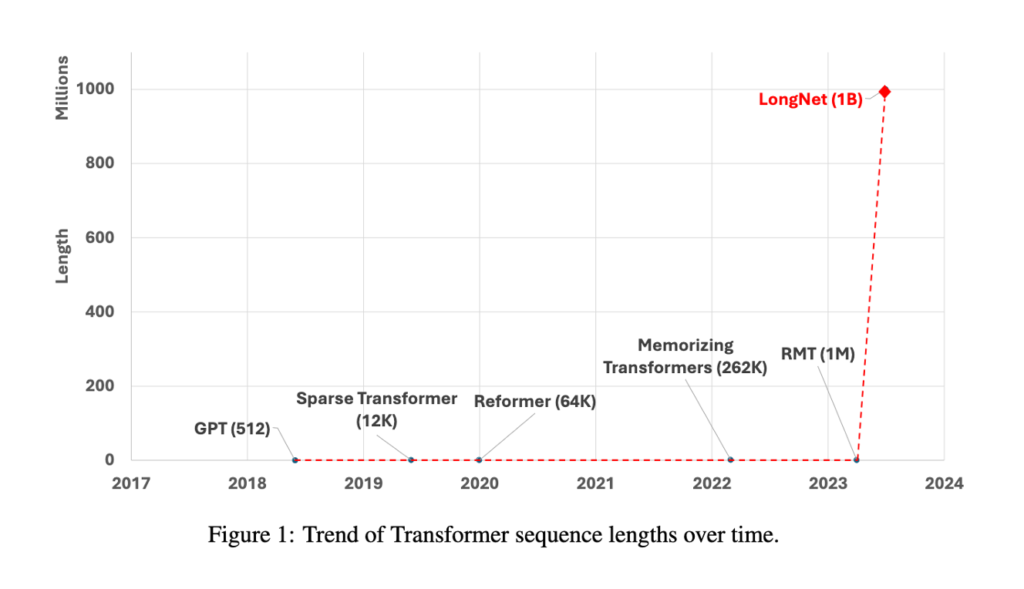
内容はTransformerの課題であるToken数が増えると、極端に処理が重たくなるattentionの計算処理を工夫することにより高速化を実現している。
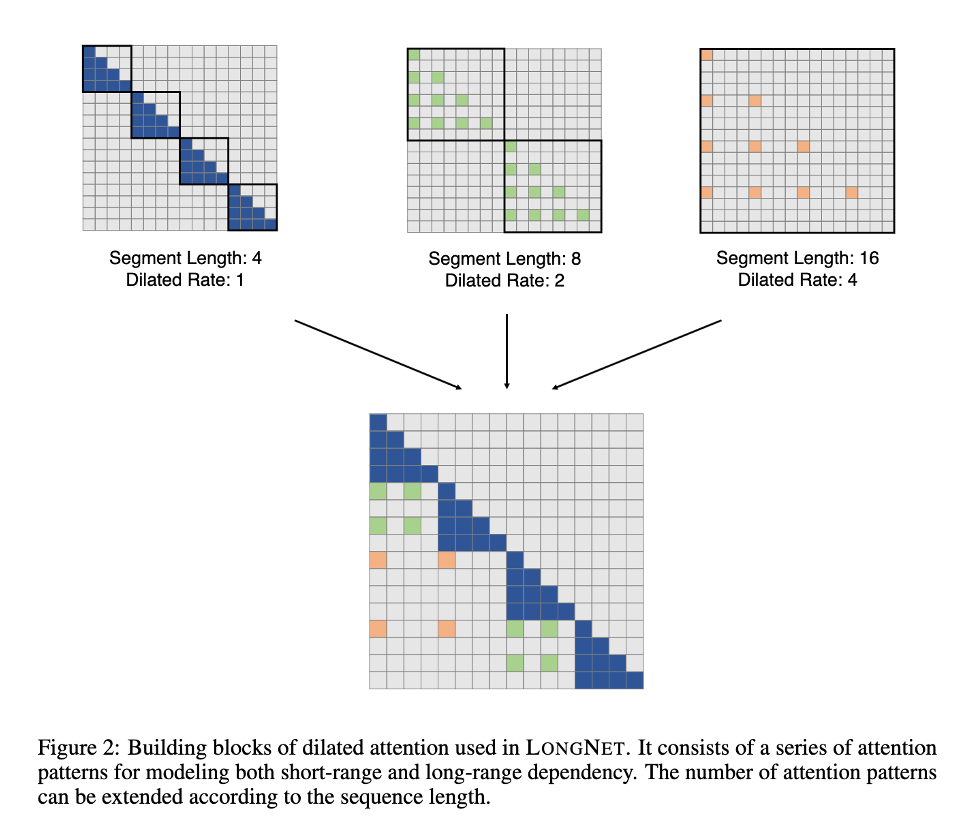
しかし論文では、言語処理に対する評価をきちっと記載していないため、精度がどの程度になるか不明である。


